
가게가 스토리
[음성 인식 기초] 데이터 전처리 팁 본문
데이터 파일 다루기
소리란?
소리라는 것은 매개체를 진동시켜 전달하는 것을 말한다.
기본적으로 밑의 그림과 같은 파형을 가지며 연속적인 값을 가지는 특징이 있다.
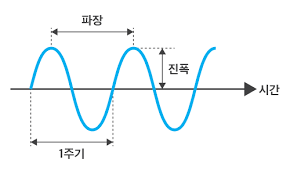
하지만 디지털 신호는 연속적인 값을 저장할 수 없는 특징을 가지고 있다.
그래서 소리의 파형을 시간단위로 쪼개어 저장하는 아이디어가 나왔다.
만약 1초에 20000번씩 파형을 쪼개어 저장한다고 하면 이 파일의 Sampling Rate는 20000Hz 또는 20kHz라고 한다.
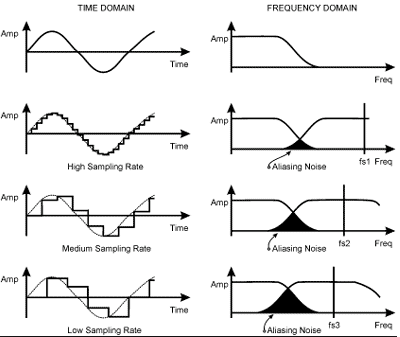
즉 Sampling Rate가 높을 수록 아날로그신호에 가까운 형태로 파일을 저장할 수 있고,
낮을 수록 촘촘히 저장하지 못해 계단형식으로 파형을 저장하게 되고, 이는 저음질을 야기한다.
그렇다고 무작정 Sampling Rate가 높을 수록 좋은 것은 아니다. 왜냐하면 사람이 들을 수 있는 주파수(가청 주파수)는 한계가 있기 때문이다.
사람마다 개인차는 있겠지만 기본적으로 20Hz ~ 20000Hz를 가청 주파수라고 한다.
(여담)
사람이 들을 수 있는 소리의 한계는 20000Hz인데 음악파일을 보면 44100Hz로 샘플링 된 파일들이 보인다.
주파수(아날로그 신호)를 디지털 정보로 변환하고, 이를 다시 아날로그 신호로 유실 없이 변환하기 위해서는 가장 빠른 주파수의 2배 이상이 필요하다는 나이퀴스트 이론이 존재한다.
때문에 가청 주파수의 최대값인 20000Hz의 2배인 40000Hz가 샘플링 되면 아날로그 신호를 유실없이 저장할 수 있다고 생각하겠지만 아니다.
가청주파수보다 높은 진동수를 가진 파형도 분명히 존재하는데 한계를 20000Hz로 정하게 되면 이 이상의 높은 주파수가 녹음이 이루어질 때 신호 왜곡현상(에일리어싱)이 발생했다.
이를 타파하고자 20000Hz이상의 주파수는 차단하는데 바로 차단 하는 것은 당시 기술력으로는 불가능했고, 점차 줄이는 방식으로 진행했다(안티 에일리어싱 필터). 이때 22000Hz까지만 소리가 담기도록 했다. 그래서 44000Hz를 Sampling Rate로 지정하려고 했으나 당시 TV수신기가 60Hz, 50Hz만 있어서 이 둘의 호환성을 맞추고자 오늘날의 44100Hz가 기준이 되었다.
음성 파일 불러오기
그래서 음성 파일을 읽어들이고자할 때 다음과 같은 라이브러리를 사용한다.
import librosa
...
file = ./train/' + file_name + '.wav'
data,sample_rate = librosa.load(file)
librosa 라이브러리에 있는 load함수를 통해 다음을 얻을 수 있다.
- data = 소리의 값
- sample_rate = Sampling Rate
즉 sample_rate를 통해 1초에 몇번을 쪼개어 저장했는지를 알 수 있고, 그 쪼개어 저장한 값을 data가 받아온 것이다.
이를 통해 "(data / sample_rate) = 파일의 길이" 임을 알 수 있다.
음성 파일 시각화
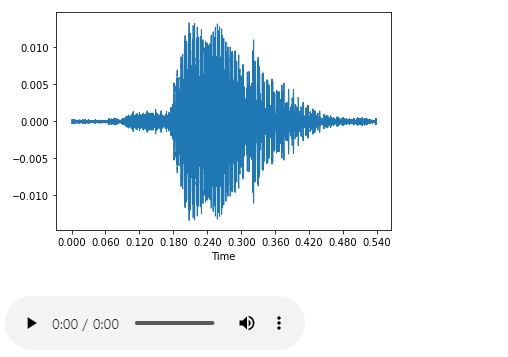
소리의 파형을 알 수 있는 코드는 다음과 같다.
import librosa.display as dsp
#파형을 그래프로 그림
dsp.waveshow(data,sr=sample_rate)
plt.show()
#소리 재생
from IPython.display import Audio
Audio(data=data,rate=sample_rate)
그럼 아래와 같은 결과가 나온다
퓨리에 변환
음성 데이터에서 특징을 추출하기 위해서는 퓨리에 변환을 거친다.
퓨리에 변환 : 입력 신호를 다양한 주파수를 가지는 주기 함수들로 분해하는 것
퓨리에 변환을 통해 어떤 주파수도 여러개의 Sin함수로 분해할 수 있다.
(여담)
영상처리에서도 배우는 내용으로, 이미지를 주파수의 형태로 변환할 수 있는데
이를 퓨리에로 변환함으로써 파일을 압축할 수 있고,
이 데이터를 역 퓨리에 변환을 통해 원래의 이미지로도 되돌릴 수 있는 역할도 수행한다.
코드는 다음과 같다.
import numpy as np
fft = np.fft.fft(data)
magnitude = np.abs(fft)
#0부터 sample_rate까지 magnitude의 개수만큼의 배열값을 만듬
frequency = np.linspace(0, sample_rate, len(magnitude))
left_frequency = frequency[:int(len(frequency)/2)]
left_magnitude = magnitude[:int(len(magnitude)/2)]
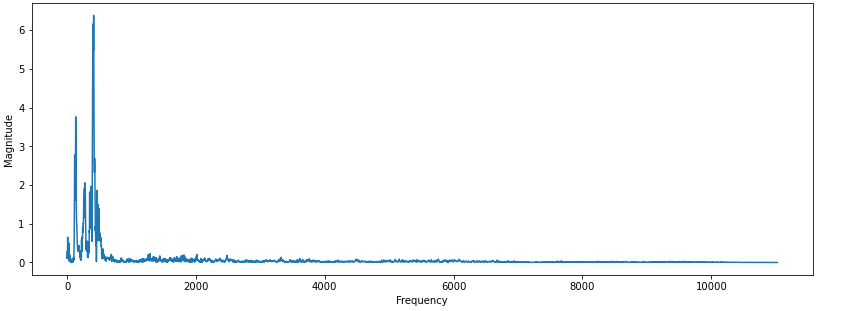
fig = plt.figure(figsize = (14,5))
plt.plot(left_frequency, left_magnitude)
plt.xlabel("Frequency")
plt.ylabel("Magnitude")
plt.show()결과
- 퓨리에 연산을 빠르게 수행해주는 fft(Fast Fourier Transform)을 사용하여 변환한다.
- 이후에 0부터 sampling_rate까지 변환한 퓨리에의 크기 만큼의 간격으로 데이터를 생성
- 퓨리에 연산 시(np.fft.fft()) 실수부와 허수부를 반환한다.
- 실수부만 보기 위해 변환값에 절대값을 씌우고, 반으로 나누면 실수부만 데이터를 확인할 수 있다.
- 실수부와 허수부는 동일한 값을 가지고 있고, 여기서는 데이터 해석의 목적만 가지므로 실수부만 본다.
Mel Spectrogram
Spectrogram은 소리나 파동을 시각화하여 파악하는 도구
Mel 은 사람의 청각기관인 달팽이관을 모티브로 따온 단어다.
사람의 달팽이관을 길게 늘어뜨렸을 때 다음과 같은 그림이 나온다.
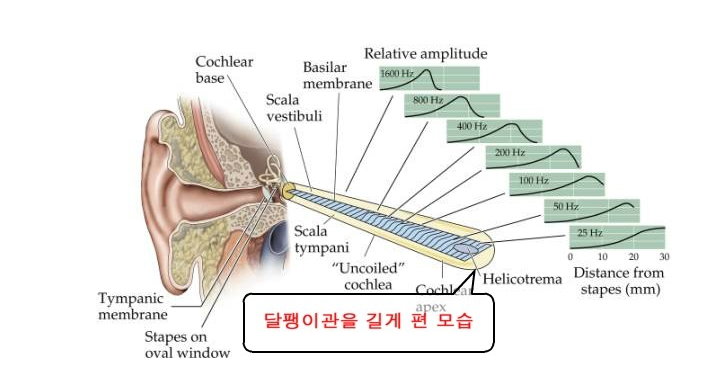
저음부에서는 통로가 넓은 만큼 감각기관이 많이 분포해있지만 고음부로 갈 수록 통로가 좁아지고, 그만큼 감각기관이 줄어들게 된다.
그래서 실제로 사람은 저음은 잘 구별하지만 고주파로 갈 수록 소리를 잘 구별하지 못하는 이유가 여기에 있다.
1000Hz 소리
2000Hz 소리
VS
10000Hz 소리
11000Hz 소리
위 2개와 아래 2개를 비교해보면
저음부에서 소리의 구별이 더 쉽다는 것을 알 수 있다.
이러한 특징을 반영하여 데이터를 다룰 수 있는데 이 기준을 Mel-scale이라고 부른다.
MFCC(Mel-frequency cepstral coefficients)
똑같은 말을 뱉어도 사람마다 말하는 길이는 천차만별이다.
때문에 음성 데이터의 길이에 의존하지 않고 특징에 의존해야한다.
사람의 음성데이터는 20~40ms내에서는 음소(현재 내고 있는 발음)이 바뀔 수 없다는 연구결과들을 기반으로 해당 시간만큼 음성 데이터를 분할하여 퓨리에 변환을 합니다.
이때 Mel-scale로 음성 데이터 구간을 정하고, 그 구간에 대한 스펙트럼을 분석하여 퓨리에 변환을 한 특징 추출방법을 MFCC라고 한다.
'인공지능 > 데이터 전처리' 카테고리의 다른 글
| Polars 기초 문법 (parquet 다루기) (0) | 2023.10.12 |
|---|
